CS전공지식 노트/4. 운영체제
운영체제 #4 : 프로세스와 스레드 2
berryberries
2023. 9. 3. 12:35
1. 프로세스 컴파일
1) 컴파일
- 인간이 이해할 수 있는 언어로 작성된 소스 코드(고수준 언어 : C, C++, Java 등)를 CPU가 이해할 수 있는 언어(저수준 언어 : 기계어)로 번역하는 작업
- 컴퓨터는 소스코드를 바로 해석 x -> 그래서 1과 0으로 된 기계어로 번역을 해주어야 한다.
2) 컴파일 과정

① 전처리 ( Preprocessing )

- 전처리기를 통해 소스코드파일(.c)을 전처리된 소스코드 파일(.i)로 변환시키는 과정
- 소스코드 주석제거 : 주석은 컴퓨터에게 필요없는 내용이여서 제거.
- 헤더파일 병합 : #include 지시문을 통해 해당 헤더 파일을 찾아 헤더 파일에 있는 모든 내용을 복사해서 소스 코드에 삽입
- 매크로 치환 : #define 지시문에 정의된 매크로를 저장하고 같은 문자열을 만나면 #define 된 내용으로 치환
② 컴파일 ( Compilation )

- 컴파일러(Compiler)를 통해 전처리된 소스 코드 파일(.i)을 어셈블리어 파일(.s)로 변환하는 과정
- 오류처리, 코드 최적화 : 어셈블리어로 변환
- Static한 영역(Data, BSS 영역)들의 메모리 할당을 수행
* 어셈블리어 : 명령어(기계어)를 사람이 이해할 수 있게 부호화한 것, CPU 명령어(기계어)와 1대1로 매칭된다.
③ 어셈블러 ( Assembly )

- 어셈블러(Assembler)를 통해 어셈블리어 파일(.s)을 오브젝트 파일(.o)로 변환하는 과정
- 소스파일이 컴파일 되면 오브젝트파일이 만들어진다.
- 오브젝트 파일은 독립적으로 실행을 하지 못한다 -> printf() 를 구현한 내용이 없어서.
- 오브젝트 파일을 실행하기 위해서는 printf 함수를 사용하는 오브젝트 파일과 printf 함수를 구현한 오브젝트 파일(libc.a 라이브러리)을 연결시키는 작업이 필요하다. -> 링킹
[참고] 오브젝트 파일
- 오브젝트 코드 : 어셈블리어 코드가 더이상 사람이 알아볼 수 없는 기계어로 변환된 코드
- 오브젝트 파일 : 오브젝트 코드들로 구성된 파일
오브젝트 파일 구성

- 오브젝트 파일 헤더 : 오브젝트 파일의 기초 정보를 가지고 있는 헤더
- 텍스트 섹션 : 기계어로 변환된 코드가 들어 있는 부분
- 데이터 섹션 : 데이터(전역 변수, 정적 변수)가 들어 있는 부분
- 심볼 테이블 섹션 : 소스 코드에서 참조되는 심볼들의 이름과 주소가 정의 되어 있는 부분. -> 다른파일에서 참조되는 심볼은 심볼테이블에 저장 x
- 재배치 정보 섹션 : 링킹 전까지 심볼의 위치를 확정할 수 없으므로 심볼의 위치가 확정 나면 바꿔야 할 내용을 적어놓은 부분
- 디버깅 정보 섹션 : 디버깅에 필요한 정보가 있는 부분
④ 링킹(Linking) 과정

- 링커를 통해 오브젝트 파일(.o)들을 묶어 실행 파일로 만드는 과정
- 오브젝트 파일들과 프로그램에서 사용하는 라이브러리 파일들을 링크하여 하나의 실행 파일을 만든다.
- 라이브러리 링킹하는 방법 : 정적 라이브러리 , 동적 라이브러리
[참고] 정적 라이브러리 vs 동적 라이브러리
정적 라이브러리 (Static Link Library)

- 링커가 프로그램에 필요로 하는 부분을 라이브러리에서 찾아 실행 파일에 복사하는 방식의 라이브러리
- 확장자 : 윈도우 환경에서는 *.lib, 리눅스 환경에서는 *.a
- 장점
- 시스템 환경 등 외부 의존도 낮음( 실행파일이 정적라이브러리를 복사해서 갖고 있다. )
- -> 실행 파일만 있으면 프로그램이 동작하는 만큼 이식성이 좋고 안정적
- 단점
- 라이브러리에 수정이 필요하면 파일 전체 다시 컴파일
- 실행파일이 갖고있는 라이브러리 만큼 파일 크기 증가
- 같은 라이브러리 가진 파일을 동시에 실행할 경우 코드 중복으로 메모리 낭비
- 정적 라이브러리 전체를 링킹하면 사용하지 않는 함수까지 전부 호출
- -> 메모리 효율성 떨어진다
동적 라이브러리 (DLL, Dynamic Link Library, Shared Library)

- 링커가 복사하지 않고 해당 내용의 주소만 갖고있다가 필요할 때마다 참조해서 가져오는 방식의 라이브러리
- 확장자 : 윈도우 환경에서는 *.dll, 리눅스 환경에서는 *.so
- 장점
- 실행 파일 크기가 작아진다 -> 여러 프로그램이 동적 라이브러리를 메모리에 올려놓고 공유해서 사용해서
- 라이브러리 수정시 실행파일을 다시 컴파일할 필요 없다 -> 동적 라이브러리만 컴파일
- -> 메모리를 효율적으로 사용할 수 있다
- 단점
- 외부 의존도 증가,이식성이 낮음 -> 실행할 때 동적 라이브러리가 필요한데 잘못 링크되어 있거나 버전 안맞으면 실행 X
- 성능 감소 -> 사용할 때마다 라이브러리를 필요한 영역으로 가져와야 한다.
2. 프로세스 메모리 구조

- 프로세스의 주소공간은 코드, 데이터, 힙, 스택으로 구성되어 있다. 이 주소 공간을 가상메모리 또는 논리적 메모리라고 부른다.
- 파일 시스템에 있는 실행 파일이 메모리에 적재될 때, 실행파일 전체가 메모리에 올라가지 않는다.
- 나머지 실행파일은 디스크의 특정영역인 스왑 영역에 존재한다.
1) 정적 할당 -> 컴파일 단계에서 메모리 할당
① 코드
- 프로그램에 내장되어 있는 소스코드가 들어가는 영역
- 사용자가 쓴 코드가 cpu가 해석할 수 있는 기계어로 변환되어 저장되는 영역
- 중간에 수정 불가능 하도록 Read-Only로 설정되어 있다.
② 데이터
- 전역변수 또는 정적변수가 저장되는 공간 -> 프로그램이 종료되면 사라지는 변수가 들어있다.
- Data segment와 BSS segment로 나뉘어져있다.
- BSS segment : 초기화 되지 않은 변수가 0으로 초기화되어 저장된다.
- Data segment : 0이 아닌 다른 값으로 할당된 변수들이 저장된다.
[참고] 정적 할당

- 컴파일단계에서 메모리를 할당하는 것
- BSS segment와 Data segment, code / text segment 로 나뉘어서 저장한다.
- 장점
- 메모리 누수를 신경쓰지 않아도 된다.
- 사용한 함수가 사라지면 자동 회수
- 단점
- 메모리 공간 크기가 정해져 있어 메모리 공간 낭비가 생길 수 있다.
더보기
//BSS segment
#include<bits/stdc++.h>
using namespace std;
int a;
int b = 0;
const int c = 0;
int main(){
static int d;
static int e = 0;
return 0;
}
// Data segment
#include<bits/stdc++.h>
using namespace std;
int a = 1;
const int b = 2;
int main(){
static int c = 3;
return 0;
}
2) 동적 할당 -> 런타임단계에서 메모리 할당
① 힙
- 프로그래머가 필요할때마다 사용하는 메모리 영역
- 런타임시 크기가 결정된다 -> 동적할당
- 자바는 heap영역에 객체가 생성되고 가비지컬렉션에서 정리된다.
- ex) 자료구조 : 동적으로 관리되기 때문에 heap영역 사용.
② 스택
- 호출된 함수의 수행을 마치고 복귀할 주소 및 데이터(지역변수, 매개변수, 리턴값 등)를 임시로 저장하는 공간
- 컴파일, 런타임할떄 크기가 결정된다. -> 동적할당
- 힙과 스택의 메모리 영역이 겹치면 안됨 -> 힙과 스택 사이의 공간을 비워둔다.
[참고] 동적 할당

- 런타임단계에서 메모리를 할당받는 것
- Stack과 Heap으로 나눈다.
- malloc(), free() 함수를 통해 관리
- 장점
- 상황에 따라 원하는 크기의 메모리를 할당 할 수 있고 원하는 크기 조절 가능하다.
- 단점
- 사용 후에는 명시적으로 사용 해제 해줘야 한다. -> 메모리 누수 가능성 있음
3. 컨텍스트 스위칭 & PCB
1) PCB ( Process Control Block )
- 운영체제에서 관리하는 프로세스에 대한 메타데이터를 저장한 데이터블록 -> 데이터의 상태정보를 저장하는 구조
- 커널 스택에 저장
- 각 프로세스가 생성될 때마다 고유의 PCB가 생성이 되고 프로세스가 종료되면 PCB는 제거된다.
- PCB에는 프로세스들의 메타데이터들이 저장되어 관리된다.
- PCB는 프로세스 상태 관리와 context switching 을 위해서 필요하다.
- PCB 는 프로세스의 중요한 정보들을 담고 있으므로 일반 사용자는 접근하지 못하게 커널스택의 가장 앞부분에서 관리한다.
[참고] 용어정리
- 커널스택
- 가상 메모리는 사용자공간과 커널공간으로 구분되는데 스택 자료구조를 기반으로 관리된다
- 사용자스택, 커널스택이라고도 불린다.
- 가상 메모리 주소의 윗부분을 말한다. -> 가장 처음 시작하는 주소값
- 커널모드에서만 접근할 수 있게 되어있으며 반대로 사용자스택은 유저모드에서만 접근가능하게 되어있습니다.
- 메타데이터
- 데이터에 관한 구조화된 데이터이자 데이터를 설명하는 작은 데이터
- 대량의 정보 가운데에서 찾고 있는 정보를 효율적으로 찾아내서 이용하기 위해 일정한 규칙에 따라 콘텐츠에 대해 부여되는 데이터이다.
2) PCB 구조

- 프로세스 상태 – 대기중, 실행 중 등 프로세스의 상태
- 프로세스 번호(PID) – 각 프로세스의 고유 식별 번호(프로세스 ID)
- 프로그램 카운터(PC) – 이 프로세스에 대해 실행될 다음 명령의 주소에 대한 포인터.
- 레지스터 – 레지스터관련 정보
- 메모리 제한 – 프로세스의 메모리 관련정보
- 열린 파일 정보 - 프로세스를 위해 열린 파일 목록들
3) 컨텍스트 스위칭
- PCB를 기반으로 프로세스의 상태를 저장하고 다시 복원시키는 과정
- 프로세스가 종료되거나 인터럽트에 의해 발생
- 스레드에도 컨텍스트 스위칭이 일어난다.
[참고] 컨텍스트 스위칭의 발생
① 멀티 태스킹
- 실행 가능한 여러개의 프로세스들이 운영체제의 스케쥴러에 의해, 우선순위에 따라 조금씩 번갈아가면서 수행된다. CPU를 할당 받는 프로세스가 변경될 때 마다 컨텍스트 스위칭이 일어난다.
② 인터럽트 핸들링
- 컴퓨터 시스템에서 예외 상황이 발생했을 때 이를 CPU 에게 알려 실행중이던 프로세스 정보를 저장하고 발생한 예외 상황을 처리하기 위한 컨텍스트 스위칭이 일어난다.
③ 사용자모드 커널모드 전환 (User and Kernel mode Switching)
- context switching 이 필수는 아니지만 운영체제에 따라 발생 가능하다.
[참고] 스레드의 컨텍스트 스위칭
스레드는 스택 영역을 제외한 모든 메모리를 공유하기 때문에 비용이 더 적고 시간도 더 적게 걸린다
① 컨텍스트 스위칭 과정

- 요청 발생 : 인터럽트나 트렙에 의해서 컨텍스트를 바꿔야 한다는 요청이 들어옴
- PCB 에 프로세스 정보 저장 : 기존에 실행중이던 프로세스 P1 와 관련된 정보들을 PCB 에 저장함
- CPU 새롭게 할당 : 운영체제는 새롭게 실행할 프로세스 P2 에 대한 정보를 해당 PCB 에서 가져와 CPU 레스터에 적재함
② 컨텍스트 스위칭의 비용
- 유후시간의 발생 : 컨텍스트 스위칭을 할 때마다 유후시간이 생겨서 CPU의 가용성이 떨어지는 비용이 발생한다.
- 캐시미스 : 프로세스가 가지고 있는 메모리 주소가 그대로 있으면 잘못된 주소 변환이 생기므로 캐시클리어 과정이 무조건 일어나게되고 이 때문에 캐시미스가 발생한다.
4. 프로세스의 상태

① 생성 상태(create or new)
- 프로세스가 생성된 상태를 의미하며 fork() 또는 exec() 함수를 통해 프로세스가 생성된 상태
- PCB가 할당된다
- fork( )
- 부모 프로세스의 주소 공간을 그대로 복사하며, 새로운 자식 프로세스를 생성하는 함수
- 주소 공간만 복사할 뿐이지 부모 프로세스의 비동기 작업 등을 상속하지는 않습니다
- exec( )
- 새롭게 프로세스를 생성하는 함수
② 대기상태 (ready)
- 처음 프로세스가 생성(create)된 이후 메모리 공간이 충분하면 메모리를 할당받고 아니면 아닌 상태로 준비큐(준비 순서열)에 들어가서 대기중인 상태
- CPU 스케줄러로부터 CPU 소유권이 넘어오기를 기다린다.
③ 대기 중단 상태(suspended ready)
- 준비큐가 꽉찬 상태 즉, 메모리 부족으로 일시 중단된 상태
④ 실행 상태(running)
- CPU 소유권과 메모리를 할당받고 인스트럭션을 수행 중인 상태
- CPU burst가 일어났다고도 표현한다.
⑤ 중단 상태(blocked)
- 어떤 이벤트가 발생한 이후 기다리며 프로세스가 차단된 상태
- wait( )를 호출하면 커널은 자식이 종료될 때까지 A를 blocked시킨다. 그리고 자식 프로세스가 종료되면 커널이 A를 깨워 Ready 상태로 만든다.
⑥ 일시 중단 상태( suspended blocked )
- 중단된 상태에서 프로세스가 실행되려고 했지만 메모리 부족으로 일시 중단된 상태
- 대기 중단과 유사
⑦ 종료 상태(terminated or exit)
- 프로세스 실행이 완료되어 해당 프로세스에 대한 자원을 반납하며 PCB가 삭제되는 상태
- 종료상태의 종류
- 자연스럽게 종료
- 비자발적 종료(abort) : 부모 프로세스가 자식 프로세스를 강제적으로 종료
- 자식 프로세스에 할당된 자원의 한계치를 넘어서거나 부모 프로세스가 종료되거나 사용자가 process.kill 등 여러 명령어로 프로세스를 종료시킬 때 발생
5. 멀티프로세싱과 멀티스레딩

1) 멀티프로세싱
- 멀티프로세스를 통해 동시에 두 가지 이상의 일을 수행할 수 있는 것
- 각 프로세스 간 메모리 구분이 필요하거나 독립된 주소 공간을 가져야 할 경우 사용한다.
- 장점
- 프로세스 중 일부에 문제가 발생되더라도 다른 프로세스에 영향을 미치지 않는다
- 격리성과 신뢰성이 높다. -> 독립된 구조
- 비용이 저렴하다 -> 여러개의 프로세스가 처리될 때 동일한 데이터를 사용한다면 하나의 디스크에 데이터를 두고 프로세서들이 공유한다.
- 단점
- 독립된 메모리 영역이기 때문에 작업량이 많을수록 오버헤드가 발생하여 성능저하가 발생 -> Context Switching때문에
- 캐시 메모리 초기화 등 무거운 작업이 진행되고 시간이 소모되는 등 오버헤드가 발생 -> Context Switching 때문
2) 멀티스레딩
- 프로세스 내 작업을 멀티스레드로 처리하는 기법
- 하나의 프로세스에 여러 스레드로 자원을 공유하며 작업을 나누어 수행한다.
- 장점
- 시스템 자원소모 감소
- 시스템 처리율 향상
- 간단한 통신 방법으로 프로그램 응답시간 단축
- 단점
- 자원을 공유하기에 동기화 문제가 발생할 수 있다. (병목현상, 데드락 등)
- 주의 깊은 설계가 필요하고 디버깅이 어렵다. (불필요 부분까지 동기화하면, 대기시간으로 인해 성능저하 발생)
- 하나의 스레드에 문제가 생기면 전체 프로세스가 영향을 받는다.
- 단일 프로세스 시스템의 경우 효과를 기대하기 어렵다.
[참고] 브라우저
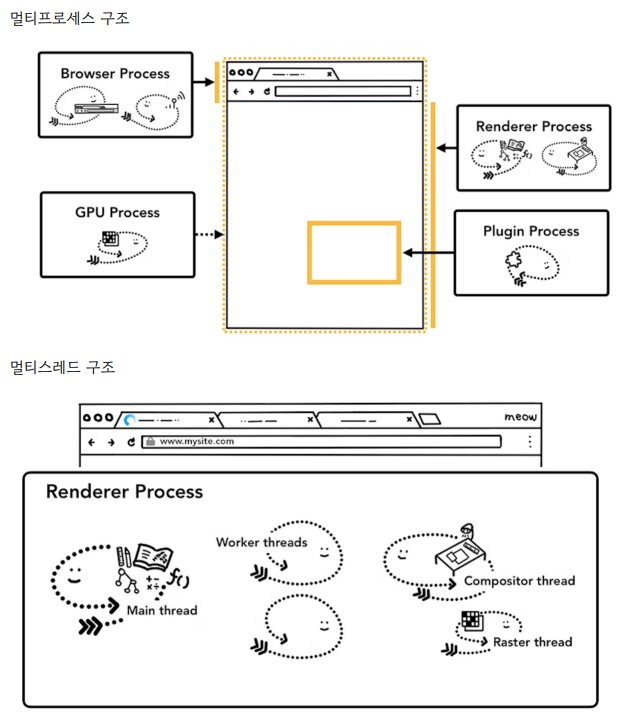
- 브라우저는 멀티프로세스 / 멀티스레드를 기반으로 멀티프로세싱, 멀티스레딩을 한다.
- 브라우저 + GPU + 랜더링 + 플러그인 + ... = 멀티 프로세스 구조로 이루어져 있다
6. IPC (IPC, Inter-Process Communication)
- 프로세스끼리 데이터를 주고받고 공유 데이터를 관리하는 메커니즘
- 종류 : 공유메모리, 파일, 소켓, 파이프, 메세지 큐
- ex) 브라우저를 띄워서 네이버서버와 HTTP 통신해서 html 등의 파일을 가져오는 것
1) 공유메모리

- 여러 프로세스가 서로 통신할 수 있도록 메모리를 공유하는 것
- 매개체를 통해 데이터를 주고 받는게 아니라 메모리 자체를 공유 -> 불필요한 데이터 복사의 오버헤드가 발생하지 않아 가장 빠르다
- 같은 메모리 영역을 여러 프로세스가 공유하기 때문에 동기화가 필요하다
- IPC중 가장 빠르다.
2) 파일
- 디스크에 저장된 데이터를 기반으로 통신하는 것
- 요즘에는 잘 안쓰는 방식
3) 소켓
- 동일한 컴퓨터의 다른 프로세스나 네트워크의 다른 컴퓨터로 네트워크 인터페이스를 통해 전송하는 데이터
- 네트워크 인터페이스(TCP, UDP, HTTP 등)를 기반으로 통신
4) 파이프
① 익명파이프(anonymous pipe or unnamed pipe)
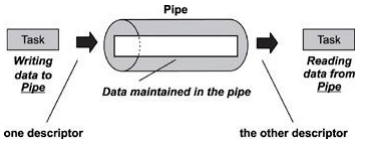

- 프로세스 사이에 FIFO 기반의 통신채널을 만들어 통신하는 것
- 파이프 하나당 단방향 통신이기 때문에 만약 양방향 통신을 하려면 2개의 익명 파이프를 만들어야한다.
- 부모,자식 프로세스간에서만 사용가능하다
- 다른 네트워크 상에서는 사용 불가능하다.
② 명명 파이프(named pipe)

- 파이프 서버와 하나 이상의 파이프 클라이언트 간의 통신을 위한 명명된 단방향 또는 이중파이프
- 클라이언트/서버통신을 위한 별도의 파이프 제공 + 여러 파이프를 동시에 사용 가능하다.
- 컴퓨터의 프로세스끼리 또는 다른 네트워크 상의 컴퓨터와도 통신 가능
- 서버, 클라이언트용 파이프를 구분해서 동작
5) 메시지 큐
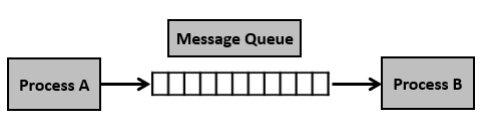
- 메시지를 큐(queue) 자료구조 형태로 관리하는 버퍼를 만들어 통신하는 것
- 커널의 전역변수 형태등 커널에서 전역적으로 관리
- 사용방법이 매우 직관적이고 간단하다
- 공유메모리를 통해 IPC를 구현하면 쓰기 일기 빈도가 높으면 동기화 때문에 기능 구현 복잡해진다 -> 메세지 큐를 사용한다.
7. 공유자원과 임계영역
1) 공유자원(shared resource)
- 시스템 안에서 각 프로세스, 스레드가 함께 접근할 수 있는 자원이나 변수
- 공동으로 이용되기 때문에 누가 언제 데이터를 읽거나 쓰느냐에 따라 그 결과가 달라질 수 있다.
- 프로세스들의 공유 자원 접근 순서를 정해서 접근하게 해야한다.
2) 경쟁 상태(race condition)
- 공유자원을 두개 이상의 프로세스가 동시에 읽거나 쓰는 상황을 말한다.
- 동시에 접근을 시도할 때 접근의 타이밍이나 순서 등이 결과값에 영향을 줄수 있는 상태
- 경쟁상태를 관리를 잘 못하면 데이터 정합성, 데이터 무결성이 침해될 수 있다.
3) 임계영역(critical section)
- 둘 이상의 프로세스,스레드가 공유자원에 접근할 때 순서등으로 결과가 달라지는 코드 영역
- 임계구역에서는 프로세스들이 동시에 작업하면 안된다
- 전역 변수 뿐만 아니라 하드웨어 자원을 사용할 때도 적용된다.
- 임계영역을 해결하기 위한 방법 : 뮤텍스, 세마포어, 모니터
① 임계영역 해결법
- 프로세스, 스레드 모두 다 적용되는 기법
- 임계영역 해결조건
- 상호배제 : 한 프로세스가 임계구역에 들어가면 다른 프로세스는 임계구역에 들어갈 수 없다.
- 한정대기 : 어떤 프로세스도 무한대기하지 않아야한다. 특정 프로세스가 임계구역에 진입하지 못하면 안된다.
- 진행의 융통성 : 한 프로세스가 다른 프로세스의 진행을 방해해서는 안된다
- 세 방법의 토대가 되는 매커니즘은 잠금(lock)이다.
뮤텍스

- 공유 자원을 lock()을 통해 잠금설정하고 사용한 후에 unlock()을 통해 잠금해제가 되는 객체 lock을 기반으로 경쟁상태를 해결
- 잠금이 설정되면 다른 프로세스나 스레드는 잠긴 코드 영역에 접근할 수 없다,
- 한번에 하나의 프로세스만 임계영역에 있을 수 있습니다.
세마포어
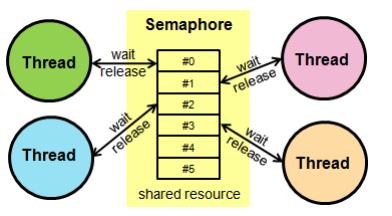
- 세마포어 변 S와 두 가지 함수 wait() 및 signal()로 공유 자원에 대한 접근을 처리한다.
- wait() : 자기차례가 올때까지 기다리는 함수
- signal() : 다음 프로세스로 순서를 넘겨주는 함수
- 프로세스나 스레드가 공유자원에 접근 : 세마포어에서 wait()작업수행
- 프로세스나 스레드가 공유자원에 접근 해제 : 마포어에서 signal()작업 수행
- 같은 세마포어에 대해서 두 프로세스가 동시에 wait(), signal() 연산을 실행할 수 없도록 보장해야한다 -> 단일 코어에서 인터럽트를 금지
- 세마포어는 바이너리 세마포어와 카운팅 세마포어로 나뉜다.
더보기
struct Semaphore {
int value;
Queue<process> q; // PCB를 담고 있음.
};
wait(Semaphore s)
{
s.value = s.value - 1;
if (s.value < 0) {
// 대기열에다 집어 넣는다.
q.push(p);
block();
} else return;
}
signal(Semaphore s)
{
s.value = s.value + 1;
if (s.value <= 0) {
// 대기열에 있던 프로세스를 끄집어내서 공유자원에 대한 작업을 진행합니다.
Process p = q.pop();
wakeup(p);
}
else return;
}[참고] 바이너리 세마포어와 카운팅 세마포어
바이너리 세마포어
- 0과 1의 두 가지 값만 가질 수 있는 세마포어
- 상호배제나 동기화를 목적으로 사용될 때 이용
- 뮤텍스락과 유사하게 동작하지만 매커니즘이 다름.
- 뮤텍스: 잠금을 기반으로 상호배제가 일어나는 ‘잠금 메커니즘’을 사용
- 세마포어 : 신호를 기반으로 상호 배제가 일어나는 ‘신호 메커니즘’을 사용
카운팅 세마포어
- 세마포어 변수가 0이상의 모든 수를 가질 수 있는 세마포어
- 생산자 - 소비자 문제 등을 해결할 때 사용한다.
모니터

- 둘 이상의 스레드나 프로세스가 공유 자원에 안전하게 접근할 수 있도록 공유자원을 숨기고 해당 접근에 대해 인터페이스만 제공하는 객체
- 공유자원에 대한 작업들을 순차적으로 처리
4) 모니터와 세마포어의 차이
| 모니터 | 세마포어 | |
| 구현 난이도 | 쉬움 | 어려움 |
| 공유자원 접근 | 한번에 하나의 프로세스만 접근가능 | 한번에 여러개 프로세스 접근 가능 |
| 상호 배제 | 자동으로 구현 | 명시적 구현 |
| 구축 기반 | 인터페이스 기반 | 정수변수 기반 |
참고 자료
- https://velog.io/@lcy960729/Semaphores-%EC%84%B8%EB%A7%88%ED%8F%AC%EC%96%B4
- https://wooody92.github.io/os/%EB%A9%80%ED%8B%B0-%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4%EC%99%80-%EB%A9%80%ED%8B%B0-%EC%8A%A4%EB%A0%88%EB%93%9C/
- https://velog.io/@nnnyeong/OS-Context-Switching-PCB-Process-Control-Block
- https://bradbury.tistory.com/224
- https://bradbury.tistory.com/226